Meta's KernelEvolve: Autonomous Kernel Optimization for Scalable AI Infrastructure
Introduction
Meta operates some of the world's largest AI services, from personalized recommendations to generative AI assistants, serving billions of users daily. Behind these systems lies a complex infrastructure of heterogeneous hardware, including NVIDIA GPUs, AMD GPUs, Meta's custom MTIA chips, and CPUs. To harness this diverse hardware efficiently, Meta developed KernelEvolve, an agentic kernel authoring system that autonomously optimizes the low-level software instructions—known as kernels—that translate high-level model operations into chip-specific code. This article explores how KernelEvolve accelerates AI infrastructure optimization, delivering significant performance gains and freeing engineers for higher-level tasks.
The Challenge of Heterogeneous Hardware
Efficiently using Meta's fleet of hardware requires writing optimized kernels for each chip generation and machine learning model architecture. While standard operations like general matrix multiplications (GEMMs) and convolutions are covered by vendor libraries, production ranking models demand many custom operators. As the number of models and hardware types grows, manual tuning by kernel experts becomes unsustainable. The combinatorial explosion of models × hardware generations creates a massive optimization workload that traditional approaches cannot scale.
KernelEvolve: An Agentic Approach
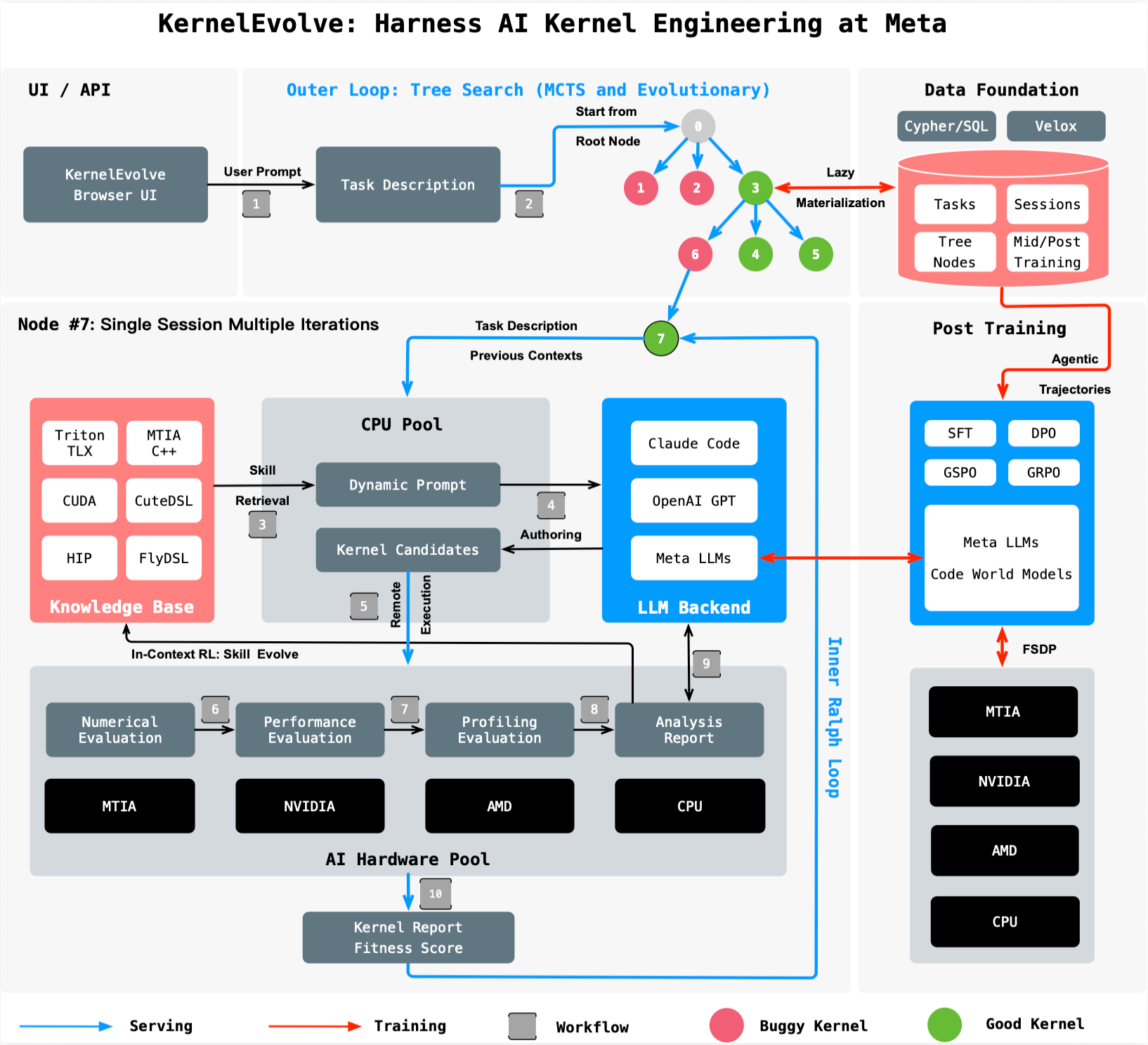
KernelEvolve treats kernel optimization as a search problem. It leverages a large language model (LLM) to generate candidate kernels and a purpose-built job harness that evaluates each candidate on real hardware. The system then feeds diagnostics back to the LLM, driving an iterative search over hundreds of alternatives. This approach compresses what used to take weeks of expert engineering effort into hours of automated exploration.
How It Works
The process begins with a high-level description of the target operation, hardware constraints, and performance goals. KernelEvolve's agent generates kernel code in high-level domain-specific languages (DSLs) like Triton, Cute DSL, and FlyDSL, or in low-level languages such as CUDA, HIP, and MTIA C++. Each candidate is compiled, run on the target hardware, and measured for throughput, latency, and resource utilization. The job harness returns these metrics to the LLM, which then proposes refinements. This closed-loop optimization continues until performance converges or a user-defined budget is reached.
Results and Impact
KernelEvolve has demonstrated remarkable improvements across Meta's infrastructure:
- Faster development: What previously required weeks of manual profiling, optimization, and cross-hardware debugging now completes in hours of automated search.
- Better performance: The Andromeda Ads model achieved over 60% inference throughput improvement on NVIDIA GPUs, and an ads model saw over 25% training throughput improvement on Meta's custom MTIA chips.
- Broad applicability: The system optimizes kernels for public and proprietary hardware, including NVIDIA GPUs, AMD GPUs, MTIA chips, and CPUs.
Broader Applicability Beyond Ads
While KernelEvolve was originally developed for Meta's Ranking Engineer Agent to optimize ad ranking models, its design is general-purpose. The system can be applied to any AI model requiring custom kernels, from computer vision to natural language processing. Its ability to target both high-level DSLs and low-level languages makes it suitable for a wide range of hardware accelerators, ensuring that Meta's entire AI ecosystem benefits from continuous kernel optimization.
Conclusion
KernelEvolve represents a major step forward in automating AI infrastructure optimization. By treating kernel authoring as a search problem and leveraging LLMs for code generation and refinement, Meta has turned a manual, expert-driven task into a scalable, autonomous process. The results—dramatic throughput gains and reduced engineering time—demonstrate the power of agentic approaches to systems optimization. As AI workloads continue to grow, systems like KernelEvolve will be essential for keeping pace with demand. Detailed technical insights are available in the paper, "KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta", presented at ISCA 2026.
Related Articles
- 10 Key Developments in Linux Swap Subsystem You Need to Know
- Fedora Asahi Remix 44 Launches: Fedora Linux Now on Apple Silicon Macs
- Closing the Local Account Security Gap: Q&A on Automated Password Rotation
- How to Deploy Unified AI Agents for Automatic Performance Optimization at Hyperscale
- KDE Secures €1.28 Million Boost from Sovereign Tech Fund for Plasma and KDE Linux Development
- Exploring Atomic Buffered Writes: PostgreSQL, Writethrough, and Kernel Development
- 10 Key Insights into AMD's HDMI 2.1 FRL Patches for the Linux AMDGPU Driver
- Unlocking Memory Efficiency: How mshare Aims to Reduce Page Table Overhead in Linux